
KI-Projekte im Unternehmen beginnen oft mit einer fachlichen Frage: Welche Aufgabe können wir schneller, genauer oder wirtschaftlicher lösen? Kurz danach kommt die zweite Frage: Dürfen wir die dafür nötigen Daten überhaupt verwenden?
Gerade im industriellen Mittelstand ist diese Spannung Alltag. Produktionsdaten enthalten vielleicht Schichtinformationen. Serviceberichte nennen Kundennamen. E-Mail-Postfächer sind voller personenbezogener Daten. Und bei generativer KI stellt sich zusätzlich die Frage, ob Eingaben an externe Anbieter übertragen, gespeichert oder zum Training genutzt werden.
Der entscheidende Punkt ist: Datenschutz und KI sollten nicht gegeneinander ausgespielt werden. Datenschutz ist kein Bremsklotz, wenn er von Anfang an in die Architektur, den Prozess und die Governance eines KI-Projekts eingebaut wird. Dann entsteht aus Unsicherheit ein belastbarer Umsetzungsrahmen, der Innovation ermöglicht und Risiken kontrollierbar macht.
Warum Datenschutz bei KI kein Nachtrag sein darf
Klassische IT-Projekte arbeiten oft mit klar definierten Datenfeldern, festen Auswertungen und bekannten Nutzergruppen. KI-Projekte sind dynamischer. Modelle erkennen Muster, kombinieren Datenquellen, erzeugen neue Inhalte oder schlagen Entscheidungen vor. Dadurch können personenbezogene Daten auch dort relevant werden, wo sie auf den ersten Blick nicht im Mittelpunkt stehen.
Die DSGVO verlangt unter anderem Rechtmäßigkeit, Zweckbindung, Datenminimierung, Transparenz, Integrität und Vertraulichkeit. Für KI bedeutet das: Unternehmen müssen erklären können, welche Daten sie verwenden, wofür sie diese verwenden, wer Zugriff hat, wie lange sie gespeichert werden und welche Schutzmaßnahmen greifen.
Hinzu kommt der EU AI Act, der seit 2024 in Kraft ist und schrittweise anwendbar wird. Er ersetzt die DSGVO nicht, sondern ergänzt sie. Während die DSGVO den Schutz personenbezogener Daten regelt, adressiert der AI Act Risiken von KI-Systemen, etwa Transparenz, menschliche Aufsicht, Datenqualität und Pflichten für Hochrisiko-Anwendungen.
Für Entscheider heißt das: Wer Datenschutz erst kurz vor dem Go-live prüft, riskiert Verzögerungen, teure Umbauten oder den Abbruch eines eigentlich sinnvollen Projekts. Wer Datenschutz dagegen in die frühe Use-Case-Auswahl integriert, kann schneller entscheiden, welche KI-Anwendungen realistisch, wirtschaftlich und rechtlich sauber umsetzbar sind.
Der richtige Startpunkt: Use Case, Datenfluss und Entscheidungstiefe
Datenschutz und KI lassen sich nur konkret bewerten, wenn der Anwendungsfall konkret ist. Die Frage lautet nicht abstrakt: Dürfen wir KI nutzen? Die bessere Frage lautet: Welche Daten verarbeitet welches KI-System zu welchem Zweck, mit welchem Ergebnis und mit welchem Einfluss auf Menschen?
Ein KI-Assistent für interne Wartungsdokumente hat ein anderes Risikoprofil als ein System, das Bewerbungen vorsortiert. Eine Qualitätsprüfung auf anonymisierten Produktbildern ist anders zu bewerten als eine Schichtplanung, die Leistungsdaten einzelner Beschäftigter berücksichtigt. Deshalb sollte jedes KI-Projekt mit einer kurzen, aber präzisen Datenflussanalyse beginnen.
| Leitfrage | Warum sie für Datenschutz und KI wichtig ist | Typisches Ergebnis |
|---|---|---|
| Welches Problem soll gelöst werden? | Verhindert Datensammlung ohne klaren Zweck | Abgrenzter Use Case statt allgemeiner KI-Wunsch |
| Welche Datenquellen werden benötigt? | Macht personenbezogene Daten sichtbar | Dateninventar mit Verantwortlichkeiten |
| Werden Personen identifiziert oder bewertbar? | Bestimmt das Risiko für Beschäftigte, Kunden oder Lieferanten | Prüfung von Rechtsgrundlage, Transparenz und Mitbestimmung |
| Wird das Ergebnis nur empfohlen oder automatisiert entschieden? | Relevant für menschliche Aufsicht und Art. 22 DSGVO | Klare Rolle des Menschen im Prozess |
| Wo läuft das System technisch? | Entscheidend für Zugriff, Übermittlung und Kontrolle | Cloud, private Cloud, On-Premise oder hybride Architektur |
| Wer betreibt und pflegt das Modell? | Klärt Rollen von Verantwortlichem, Auftragsverarbeiter und Anbieter | Vertragliche und technische Schutzmaßnahmen |
Diese Fragen sind kein bürokratischer Zusatz. Sie sparen Zeit, weil sie früh zeigen, ob ein Projekt mit vorhandenen Daten, bestehenden Systemen und vertretbarem Risiko umgesetzt werden kann.
Vier Prinzipien für datenschutzsichere KI-Projekte
Zweckbindung: KI braucht klare Grenzen
KI-Systeme wirken besonders attraktiv, wenn sie viele Datenquellen gleichzeitig nutzen. Genau darin liegt aber ein Datenschutzrisiko. Daten, die ursprünglich für Wartung, Qualitätssicherung oder Kundenservice erhoben wurden, dürfen nicht automatisch für beliebige KI-Auswertungen verwendet werden.
Deshalb sollte jeder Use Case eine klare Zweckbeschreibung haben. Eine gute Zweckbeschreibung ist fachlich verständlich, technisch prüfbar und organisatorisch durchsetzbar. Sie beantwortet, welche Aufgabe das System unterstützt, welche Daten dafür notwendig sind und welche Nutzungen ausdrücklich ausgeschlossen sind.
Datenminimierung: Nicht jedes mögliche Datum ist erforderlich
Viele KI-Projekte starten mit der Annahme, dass mehr Daten automatisch bessere Ergebnisse liefern. Das stimmt nicht immer. In der Praxis verbessert Datenmenge allein weder Datenqualität noch Modellleistung. Oft sind wenige saubere, relevante und gut beschriebene Datenquellen wertvoller als große, unstrukturierte Datenbestände.
Datenminimierung bedeutet nicht, KI künstlich auszubremsen. Es bedeutet, den fachlichen Nutzen gegen das Datenschutzrisiko abzuwägen. Können Namen entfernt werden? Reicht eine Abteilung statt einer Person? Lassen sich Freitextfelder vor der Verarbeitung bereinigen? Können sensible Daten aus Prompts ausgeschlossen werden?
Transparenz: Betroffene müssen verstehen, was passiert
Wenn Beschäftigte, Kunden oder Lieferanten von KI-Verarbeitung betroffen sind, brauchen sie verständliche Informationen. Das gilt besonders, wenn KI Vorschläge erzeugt, Prioritäten setzt, Risiken bewertet oder Arbeitsschritte beeinflusst.
Transparenz ist mehr als eine Datenschutzerklärung. Führungskräfte sollten erklären können, warum das System eingesetzt wird, welche Daten verarbeitet werden, welche Grenzen bestehen und wer im Zweifel verantwortlich ist. Eine gute Kommunikationsstrategie reduziert Widerstand und stärkt Akzeptanz. Wer das Thema im Betrieb strukturiert angehen möchte, findet in der Praxis auch Ansätze, wie Unternehmen Mitarbeitende frühzeitig mitnehmen.
Kontrolle: KI darf nicht zur Blackbox im Prozess werden
Datenschutz und KI werden dann belastbar, wenn Verantwortung sichtbar bleibt. Das betrifft technische Protokollierung, fachliche Freigaben, Rollenrechte und Eskalationswege. Bei höherem Risiko sollte ein Mensch nicht nur theoretisch, sondern praktisch in der Lage sein, ein KI-Ergebnis zu prüfen, zu korrigieren oder abzulehnen.
Gerade im Mittelstand ist dafür keine überdimensionierte Konzernbürokratie nötig. Entscheidend ist eine pragmatische Governance: klare Zuständigkeiten, dokumentierte Use Cases, Risikoabstufungen und regelmäßige Überprüfung. Eine gute Ergänzung ist ein Rahmen für praxistaugliche KI-Governance, der technische, rechtliche und wirtschaftliche Anforderungen zusammenführt.
Typische KI-Anwendungen und ihre Datenschutzfragen
Nicht jeder KI-Anwendungsfall ist gleich kritisch. Viele produktive Einstiegsszenarien lassen sich datenschutzarm gestalten, wenn Datenflüsse sauber geplant werden. Andere Anwendungen benötigen eine intensivere Prüfung, etwa eine Datenschutz-Folgenabschätzung oder zusätzliche arbeitsrechtliche Abstimmung.
| KI-Anwendung | Datenschutzrelevanz | Kritische Fragen | Sinnvolle Schutzmaßnahmen |
|---|---|---|---|
| Wissensassistent für interne Dokumente | Mittel, wenn Dokumente personenbezogene Daten enthalten | Welche Dokumente werden indexiert? Wer darf welche Inhalte abrufen? | Rechtekonzept, Dokumentenbereinigung, Protokollierung, keine ungeprüfte Volltextfreigabe |
| Automatisierte E-Mail-Klassifikation | Mittel bis hoch, da E-Mails oft personenbezogen sind | Werden Inhalte an externe Dienste übertragen? Wie werden sensible Inhalte erkannt? | Vorfilterung, Auftragsverarbeitung, Löschkonzept, Zugriffsbeschränkung |
| Qualitätsprüfung mit Bilddaten | Niedrig bis hoch, je nach Motiv | Sind Personen, Arbeitsplätze oder personenbezogene Merkmale erkennbar? | Bildausschnitt begrenzen, Anonymisierung, Edge- oder On-Premise-Verarbeitung |
| Predictive Maintenance | Häufig niedrig, kann aber Beschäftigtendaten berühren | Lassen sich Maschinenzustände einzelnen Mitarbeitenden zuordnen? | Aggregation, klare Zweckbindung, Trennung von Maschinen- und Personaldaten |
| KI-Unterstützung im HR-Prozess | Hoch | Werden Menschen bewertet, sortiert oder benachteiligt? | Strenge Rechtsprüfung, Bias-Tests, Transparenz, menschliche Entscheidung, Mitbestimmung |
| Rechnungs- und Belegverarbeitung | Mittel | Enthalten Belege Namen, Kontaktdaten oder Bankdaten? | Datenminimierung, Verschlüsselung, Rollenrechte, Löschfristen |
Die Tabelle zeigt: Datenschutz ist keine Ja-nein-Frage. Oft geht es darum, denselben Nutzen mit weniger riskanter Datenverarbeitung zu erreichen.
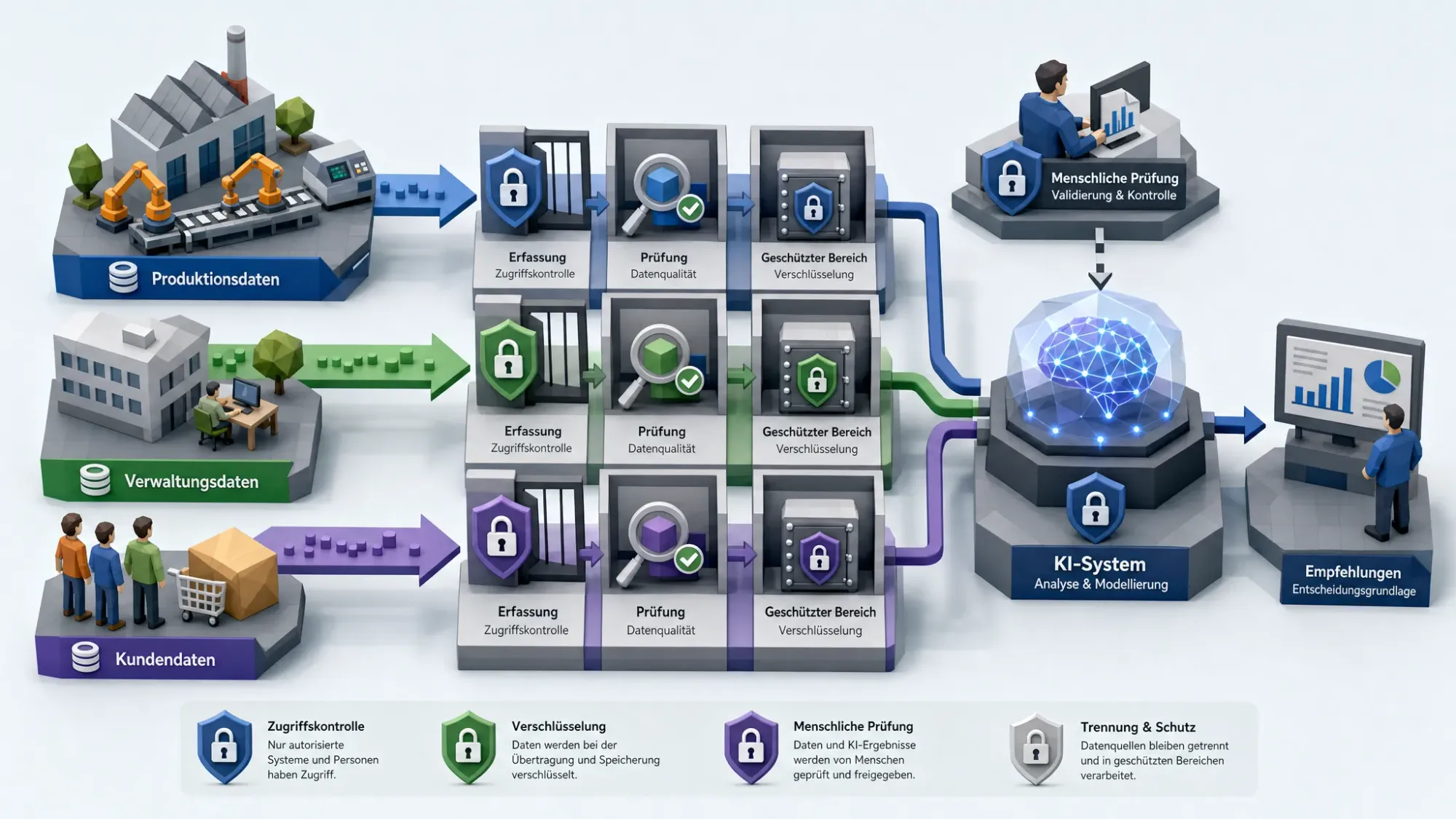
Technische Maßnahmen, die Datenschutz und KI zusammenbringen
Viele Datenschutzrisiken lassen sich durch Architekturentscheidungen reduzieren. Das beginnt bei der Frage, ob ein Modell Daten wirklich lernen muss oder ob es reicht, Informationen kontrolliert bereitzustellen. Bei vielen Unternehmensassistenten ist Retrieval Augmented Generation sinnvoll: Das Modell greift auf definierte Dokumentenbestände zu, statt vertrauliche Inhalte dauerhaft in ein Modelltraining einfließen zu lassen.
Auch die Betriebsform spielt eine große Rolle. Cloud-Dienste können geeignet sein, wenn Verträge, Speicherorte, Zugriffskontrollen und Löschprozesse passen. Für besonders sensible Daten kann eine private Cloud, eine isolierte Umgebung oder eine On-Premise-Bereitstellung sinnvoll sein. Wichtig ist, diese Entscheidung nicht pauschal, sondern nach Risiko, Nutzen und Integrationsbedarf zu treffen.
Zu den wichtigsten technischen und organisatorischen Maßnahmen gehören Verschlüsselung, rollenbasierte Zugriffe, Protokollierung, Pseudonymisierung, Trennung von Test- und Produktivdaten, definierte Löschfristen und klare Regeln für Prompts. Bei generativer KI sollten Unternehmen außerdem festlegen, welche Daten Mitarbeitende nicht eingeben dürfen und welche Ausgaben vor der Weiterverwendung geprüft werden müssen.
Ein weiterer Hebel ist Datenqualität. Schlechte Daten erhöhen nicht nur fachliche Fehler, sondern auch Datenschutzrisiken. Veraltete Personendaten, unklare Freitextfelder oder gemischte Datenablagen erschweren Zweckbindung und Zugriffskontrolle. Eine Datenqualitätsprüfung vor dem Proof of Concept ist deshalb kein Luxus, sondern eine zentrale Voraussetzung für sichere KI.
Organisatorisch sauber aufsetzen: Rollen, Verträge und Betriebsrat
Datenschutzsichere KI entsteht nicht allein in der IT-Abteilung. Beteiligt sind in der Regel Fachbereich, Datenschutzbeauftragte, IT-Sicherheit, Einkauf, Rechtsabteilung, Betriebsrat und Geschäftsführung. Je früher diese Rollen eingebunden werden, desto geringer ist das Risiko späterer Blockaden.
Für externe KI-Anbieter müssen Rollen und Verantwortlichkeiten sauber geklärt werden. Ist der Anbieter Auftragsverarbeiter? Gibt es gemeinsame Verantwortlichkeit? Werden Daten zu eigenen Zwecken verarbeitet? Wo findet die Verarbeitung statt? Gibt es Unterauftragnehmer? Diese Fragen gehören vor die Pilotphase, nicht erst in den Produktivvertrag.
Im Beschäftigungskontext kommt der Betriebsrat hinzu. Sobald KI-Systeme Verhalten oder Leistung von Beschäftigten überwachen können oder Arbeitsprozesse wesentlich verändern, sind Mitbestimmungsrechte zu prüfen. Selbst wenn ein System nicht zur Überwachung gedacht ist, kann eine technische Möglichkeit dafür ausreichen, um Diskussionen auszulösen. Transparenz, klare Zweckgrenzen und nachvollziehbare Protokolle helfen, Vertrauen aufzubauen.
Ein pragmatischer Fahrplan für den Mittelstand
Der Mittelstand braucht keine monatelange Grundsatzdebatte, bevor ein KI-Projekt starten kann. Er braucht einen schlanken Prozess, der rechtliche, technische und wirtschaftliche Fragen früh genug zusammenführt. Bewährt hat sich ein stufenweises Vorgehen.
| Phase | Ziel | Konkretes Ergebnis |
|---|---|---|
| Use-Case-Screening | Nutzen und Risiko grob bewerten | Priorisierte KI-Ideen mit Datenschutzampel |
| Datenprüfung | Datenquellen, Qualität und Personenbezug verstehen | Dateninventar, Lückenanalyse, erste Schutzmaßnahmen |
| Rechts- und Rollenklärung | DSGVO, AI Act, Verträge und Mitbestimmung einordnen | Rechtsgrundlage, Verantwortlichkeiten, notwendige Dokumentation |
| Proof of Concept | Fachlichen Nutzen mit begrenztem Risiko testen | Prototyp in kontrollierter Umgebung, ROI-Indikation, Risikobewertung |
| Produktivsetzung | Sicheren Betrieb ermöglichen | Zugriffskonzept, Monitoring, Schulung, Lösch- und Änderungsprozess |
| Regelbetrieb | Wirksamkeit und Compliance sichern | Regelmäßige Reviews, Modellkontrolle, Anpassung an neue Anforderungen |
Der Vorteil dieses Vorgehens liegt in der Entscheidungsfähigkeit. Die Geschäftsführung sieht früh, ob ein Use Case wirtschaftlich tragfähig ist. Datenschutz und IT-Sicherheit sehen früh, welche Risiken entstehen. Der Fachbereich sieht früh, ob die Lösung im Alltag funktioniert.
Warnsignale, bei denen Unternehmen genauer hinsehen sollten
Einige Muster zeigen, dass ein KI-Projekt datenschutzseitig noch nicht reif ist:
- Der Zweck des Systems lässt sich nicht in zwei bis drei Sätzen erklären.
- Es ist unklar, welche Datenquellen verarbeitet werden.
- Testdaten werden aus Produktivsystemen kopiert, ohne Bereinigung oder Zugriffskontrolle.
- Prompts enthalten regelmäßig Kunden-, Beschäftigten- oder Vertragsdaten.
- Der Anbieter macht keine belastbaren Aussagen zu Speicherung, Training, Unterauftragnehmern oder Datenstandorten.
- KI-Ergebnisse beeinflussen Menschen, aber es gibt keine menschliche Prüfung oder Einspruchsmöglichkeit.
Diese Warnsignale bedeuten nicht automatisch, dass das Projekt gestoppt werden muss. Sie zeigen aber, dass vor dem nächsten Schritt Architektur, Verträge oder Prozesse nachgeschärft werden sollten.
Fazit: Datenschutz macht KI belastbar
Datenschutz und KI sicher zusammen zu denken bedeutet nicht, Innovation zu verlangsamen. Es bedeutet, KI so aufzusetzen, dass sie im Unternehmen dauerhaft genutzt werden kann. Gerade für mittelständische Industrieunternehmen ist das entscheidend: KI soll Produktions- und Verwaltungsprozesse verbessern, ohne Vertrauen, Datensicherheit oder Compliance zu gefährden.
Der Schlüssel liegt in der frühen Verbindung von Use Case, Datenfluss, Rechtsgrundlage, technischer Architektur und Governance. Wenn diese Elemente zusammen betrachtet werden, entstehen Lösungen, die nicht nur im Pilotprojekt funktionieren, sondern auch im operativen Betrieb Bestand haben.
Häufige Fragen zu Datenschutz und KI im Unternehmen
Darf ein Unternehmen personenbezogene Daten für KI verwenden? Ja, aber nur mit einer passenden Rechtsgrundlage, einem klaren Zweck und angemessenen Schutzmaßnahmen. Je nach Anwendungsfall können zusätzlich Transparenzpflichten, eine Datenschutz-Folgenabschätzung oder Mitbestimmungsrechte relevant sein.
Ist generative KI im Unternehmen grundsätzlich datenschutzkritisch? Nicht grundsätzlich, aber sie erfordert klare Regeln. Kritisch wird es, wenn personenbezogene oder vertrauliche Daten in externe Systeme eingegeben werden, ohne dass Speicherung, Training, Zugriff und Löschung geklärt sind.
Wann ist eine Datenschutz-Folgenabschätzung bei KI nötig? Sie ist erforderlich, wenn eine Verarbeitung voraussichtlich ein hohes Risiko für Rechte und Freiheiten natürlicher Personen mit sich bringt. Das kann etwa bei systematischer Bewertung von Personen, umfangreicher Verarbeitung sensibler Daten oder bestimmten Beschäftigtenanwendungen der Fall sein.
Reicht es, personenbezogene Daten zu anonymisieren? Echte Anonymisierung kann Datenschutzrisiken stark reduzieren, ist aber anspruchsvoll. Wenn Daten mit vertretbarem Aufwand wieder einer Person zugeordnet werden können, handelt es sich meist um Pseudonymisierung, die weiterhin unter die DSGVO fällt.
Was sollten Unternehmen vor einem KI-Proof-of-Concept klären? Vor einem PoC sollten Zweck, Datenquellen, Personenbezug, technische Umgebung, Anbieterrolle, Zugriffskonzept und Erfolgskriterien geklärt sein. So bleibt der Test beherrschbar und liefert belastbare Entscheidungsgrundlagen.
KI sicher und wirksam in die Umsetzung bringen
Wenn Sie KI im Unternehmen nutzen möchten, sollten Datenschutz, Datenqualität und Wirtschaftlichkeit von Beginn an gemeinsam betrachtet werden. So vermeiden Sie Insellösungen, rechtliche Unsicherheiten und Pilotprojekte ohne belastbaren Nutzen.
skillbyte unterstützt mittelständische Industrieunternehmen dabei, passende KI-Anwendungsfälle zu identifizieren, Datenqualität zu bewerten, Proofs of Concept aufzusetzen und KI-Lösungen sicher in bestehende Systeme zu integrieren. Dazu gehören auch Fragen zu Datenschutz, On-Premise-Optionen, ROI-Abschätzung und Enablement der beteiligten Teams.
Der nächste sinnvolle Schritt ist meist kein Großprojekt, sondern ein strukturiertes Use-Case- und Daten-Screening. Daraus entsteht eine klare Entscheidungsgrundlage: Welche KI lohnt sich, welche Daten werden benötigt und wie lässt sich die Lösung sicher betreiben?
