Viele mittelständische Unternehmen wollen KI einsetzen, aber der erste Einwand kommt oft sofort: Was ist mit dem Datenschutz? Diese Frage ist berechtigt. Gerade im industriellen Mittelstand treffen Produktionsdaten, Kundendokumente, Lieferanteninformationen, Mitarbeiterdaten und wertvolles Prozesswissen zusammen. Wer hier unkontrolliert experimentiert, riskiert nicht nur DSGVO-Probleme, sondern auch Know-how-Abfluss und Vertrauensverlust.
Die gute Nachricht: KI und Datenschutz lassen sich sicher zusammenbringen, wenn Datenschutz nicht als Hürde am Ende betrachtet wird, sondern als Architekturprinzip von Anfang an. Für Entscheider bedeutet das: Nicht jedes KI-Projekt braucht personenbezogene Daten. Nicht jedes Projekt muss in die Cloud. Und nicht jeder Use Case ist regulatorisch gleich riskant.
Dieser Beitrag zeigt, wie mittelständische Unternehmen KI-Projekte pragmatisch, wirtschaftlich und datenschutzbewusst aufsetzen, von der ersten Use-Case-Idee bis zum produktiven Betrieb.
Warum KI und Datenschutz im Mittelstand besonders wichtig sind
Im Mittelstand ist die Datenlage häufig anders als in Konzernen. Daten liegen in ERP-Systemen, Excel-Dateien, Maschinensteuerungen, Dokumentenablagen, E-Mail-Postfächern oder Spezialsoftware. Prozesse sind historisch gewachsen, Verantwortlichkeiten sind verteilt, und viel Expertenwissen steckt in den Köpfen erfahrener Mitarbeitender.
Genau dort kann KI großen Nutzen stiften: Qualitätsabweichungen früher erkennen, Produktionsplanung verbessern, Dokumente automatisch auswerten, Wissen auffindbar machen oder Verwaltungsprozesse beschleunigen. Gleichzeitig entstehen Datenschutzfragen, sobald personenbezogene Daten verarbeitet werden. Dazu gehören nicht nur offensichtliche Daten wie Namen, Adressen oder Personalnummern. Auch Logdaten, Schichtpläne, E-Mail-Inhalte, Nutzerkennungen, Kameraaufnahmen oder Freitextfelder können personenbezogen sein.
Die Datenschutz-Grundverordnung verlangt unter anderem Zweckbindung, Datenminimierung, Transparenz, angemessene Sicherheit und eine Rechtsgrundlage für die Verarbeitung personenbezogener Daten. Für KI-Projekte heißt das: Der Nutzen muss klar sein, die Daten müssen passen, und die Verarbeitung muss technisch wie organisatorisch kontrolliert werden.
Wichtig ist auch: Datenschutz ist nicht dasselbe wie Datensicherheit. Datenschutz schützt die Rechte natürlicher Personen. Datensicherheit schützt Daten vor Verlust, Manipulation oder unberechtigtem Zugriff. In KI-Projekten braucht es beides.
Der erste Schritt: Welche Daten braucht der KI-Use-Case wirklich?
Viele Datenschutzrisiken entstehen, weil KI-Projekte zu breit starten. Es werden Daten gesammelt, bevor der konkrete Zweck sauber definiert ist. Besser ist der umgekehrte Weg: Erst das Geschäftsproblem beschreiben, dann prüfen, welche Daten für die Lösung wirklich notwendig sind.
Ein Beispiel: Wenn ein Unternehmen Ausschuss in der Produktion reduzieren will, werden möglicherweise Maschinendaten, Prozessparameter, Chargeninformationen und Qualitätsmesswerte benötigt. Personenbezogene Daten spielen dabei oft nur eine Nebenrolle oder gar keine Rolle. Wenn jedoch Bedienerkennungen, Schichtdaten oder Fehlerkommentare aus Freitextfeldern einbezogen werden, ändert sich die Bewertung.
Eine einfache Datenklassifizierung hilft, früh Klarheit zu schaffen.
| Datenart | Typische Beispiele im Mittelstand | Datenschutzrelevanz | Geeignete Schutzmaßnahmen |
|---|---|---|---|
| Maschinendaten | Sensorwerte, Temperaturen, Laufzeiten, Taktzeiten | Niedrig, sofern kein Personenbezug besteht | Zugriffskontrolle, Integritätsschutz, klare Datenverantwortung |
| Prozess- und Qualitätsdaten | Prüfwerte, Chargen, Reklamationen, Fehlertypen | Niedrig bis mittel | Pseudonymisierung, Trennung von Personen- und Prozessdaten |
| Geschäftsdokumente | Rechnungen, Angebote, Verträge, Lieferscheine | Mittel bis hoch | Datenminimierung, Rollenrechte, Verschlüsselung, Löschkonzept |
| Kommunikationsdaten | E-Mails, Tickets, Chatverläufe, Gesprächsnotizen | Hoch | Zweckbegrenzung, Filterung, Berechtigungskonzepte, Transparenz |
| Bild- und Videodaten | Qualitätsbilder, Kameras an Linien, Zutrittsbereiche | Hoch | Verpixelung, Edge-Verarbeitung, kurze Speicherfristen, strenge Zugriffe |
| Beschäftigtendaten | Schichtpläne, Leistungsdaten, HR-Daten, Nutzerlogs | Sehr hoch | Betriebsrat einbinden, DSFA prüfen, Human-in-the-Loop, klare Grenzen |
Ein zentraler Punkt wird oft unterschätzt: Pseudonymisierung ist nicht dasselbe wie Anonymisierung. Pseudonymisierte Daten bleiben personenbezogen, wenn eine Zuordnung grundsätzlich möglich ist. Anonymisierte Daten fallen nur dann nicht mehr unter die DSGVO, wenn eine Reidentifikation mit realistischem Aufwand ausgeschlossen ist.
DSGVO, EU AI Act und Betriebsrat: Was Entscheider einordnen sollten
Für KI-Projekte im Mittelstand sind meist drei Ebenen relevant: Datenschutzrecht, KI-Regulierung und betriebliche Mitbestimmung.
Die DSGVO greift immer dann, wenn personenbezogene Daten verarbeitet werden. Unternehmen müssen dann unter anderem die Rechtsgrundlage, den Zweck, die Betroffenenrechte, Löschfristen, technische und organisatorische Maßnahmen sowie mögliche Auftragsverarbeitungen prüfen. Bei voraussichtlich hohem Risiko für Rechte und Freiheiten natürlicher Personen kann eine Datenschutz-Folgenabschätzung erforderlich sein.
Der EU AI Act ergänzt diese Perspektive. Er ersetzt die DSGVO nicht, sondern legt zusätzliche Anforderungen an bestimmte KI-Systeme fest, vor allem bei risikoreichen Anwendungen. Dazu können je nach Kontext Systeme in Beschäftigung, Bildung, kritischer Infrastruktur oder sicherheitsrelevanten Bereichen gehören. Für Unternehmen ist entscheidend, den eigenen Use Case früh in eine Risikokategorie einzuordnen.
In Deutschland kommt bei KI-Systemen mit möglichem Bezug zu Mitarbeitenden häufig der Betriebsrat hinzu. Nach § 87 BetrVG bestehen Mitbestimmungsrechte, wenn technische Einrichtungen eingeführt werden, die Verhalten oder Leistung von Beschäftigten überwachen können. Das gilt nicht erst, wenn Überwachung beabsichtigt ist. Schon die technische Möglichkeit kann relevant sein.
Praktisch bedeutet das: Datenschutzbeauftragte, IT-Sicherheit, Fachbereich und Betriebsrat sollten nicht erst beim Rollout informiert werden. Je früher diese Stakeholder eingebunden sind, desto geringer ist das Risiko von Verzögerungen, Ablehnung oder teuren Nacharbeiten.
Sieben Prinzipien für datenschutzsichere KI-Projekte
1. Den Zweck präzise definieren
Ein KI-Projekt sollte mit einer konkreten Frage starten, nicht mit einem Tool. Statt „Wir wollen generative KI nutzen“ ist ein Ziel wie „Wir wollen technische Serviceanfragen automatisch klassifizieren und passende Wissensartikel vorschlagen“ deutlich besser prüfbar.
Der Zweck bestimmt, welche Daten verarbeitet werden dürfen, welche Ergebnisse erwartet werden und welche Risiken entstehen. Gleichzeitig ist er die Basis für ROI-Betrachtung und Erfolgsmessung. Mehr dazu, wie Unternehmen sinnvolle KI-Vorhaben priorisieren, finden Sie im Beitrag Künstliche Intelligenz im Mittelstand richtig einsetzen.
2. Daten vor dem PoC bewerten
Ein Proof of Concept ist nur dann aussagekräftig, wenn die Daten realistisch sind. Gleichzeitig sollte ein PoC nicht unkontrolliert mit produktiven Echtdaten starten. Sinnvoll ist eine vorgeschaltete Datenprüfung: Welche Systeme sind betroffen? Welche Datenfelder enthalten Personenbezug? Welche Qualität haben die Daten? Welche Daten können entfernt, maskiert oder synthetisch ersetzt werden?
Diese Bewertung ist keine reine Compliance-Aufgabe. Schlechte Datenqualität führt zu schlechten KI-Ergebnissen. Datenschutz und technische Qualität zahlen daher auf dasselbe Ziel ein: robuste, belastbare KI-Systeme.
3. Datenminimierung technisch umsetzen
Datenminimierung klingt einfach, scheitert aber oft in der Umsetzung. In KI-Projekten bedeutet sie: Nur die Daten verwenden, die für den Zweck wirklich notwendig sind. Freitextfelder, Anhänge, vollständige Dokumente oder Loghistorien sollten nicht pauschal in Modelle oder Vektordatenbanken übernommen werden.
Technisch helfen Vorverarbeitung, Maskierung, Feldfilter, Berechtigungsschnittstellen und getrennte Datenräume. Bei Dokumentenautomatisierung kann es zum Beispiel sinnvoll sein, personenbezogene Informationen vor der Modellverarbeitung zu entfernen, sofern sie für die Aufgabe nicht relevant sind.
4. Architektur passend zum Risiko wählen
Nicht jeder KI-Use-Case braucht dieselbe Architektur. Ein internes Assistenzsystem für öffentliche Produktinformationen stellt andere Anforderungen als ein KI-System, das sensible Vertragsdaten, Entwicklungsunterlagen oder Beschäftigtendaten verarbeitet.
| Architektur | Geeignet für | Datenschutz- und Sicherheitsaspekte |
|---|---|---|
| Public SaaS KI-Tool | Niedrig sensible Aufgaben, allgemeine Texte, Ideation | Auftragsverarbeitung, Datenregion, Logging, Trainingsnutzung und Tool-Freigabe prüfen |
| Enterprise Cloud in EU-Region | Fachanwendungen mit kontrolliertem Datenzugriff | Rollenrechte, Verschlüsselung, Mandantentrennung, AV-Vertrag, Auditierbarkeit |
| Private Cloud | Sensible Unternehmensdaten mit Skalierungsbedarf | Höhere Kontrolle, klare Betriebsverantwortung, Monitoring und Patch-Prozesse nötig |
| On-Premise KI | Kritisches Know-how, regulierte Daten, strenge Datenhoheit | Maximale Kontrolle, aber höherer Betriebs- und Infrastrukturaufwand |
| Hybride RAG-Architektur | Wissenssuche über interne Dokumente | Berechtigungsprüfung auf Dokumentebene, sichere Vektordatenbank, Quellenanzeige |
Gerade für den industriellen Mittelstand sind hybride Architekturen oft attraktiv: Sensible Daten bleiben im Unternehmen oder in kontrollierten Umgebungen, während ausgewählte KI-Komponenten über definierte Schnittstellen angebunden werden. Bei besonders sensiblen Szenarien kann ein On-Premise-Deployment sinnvoll sein.
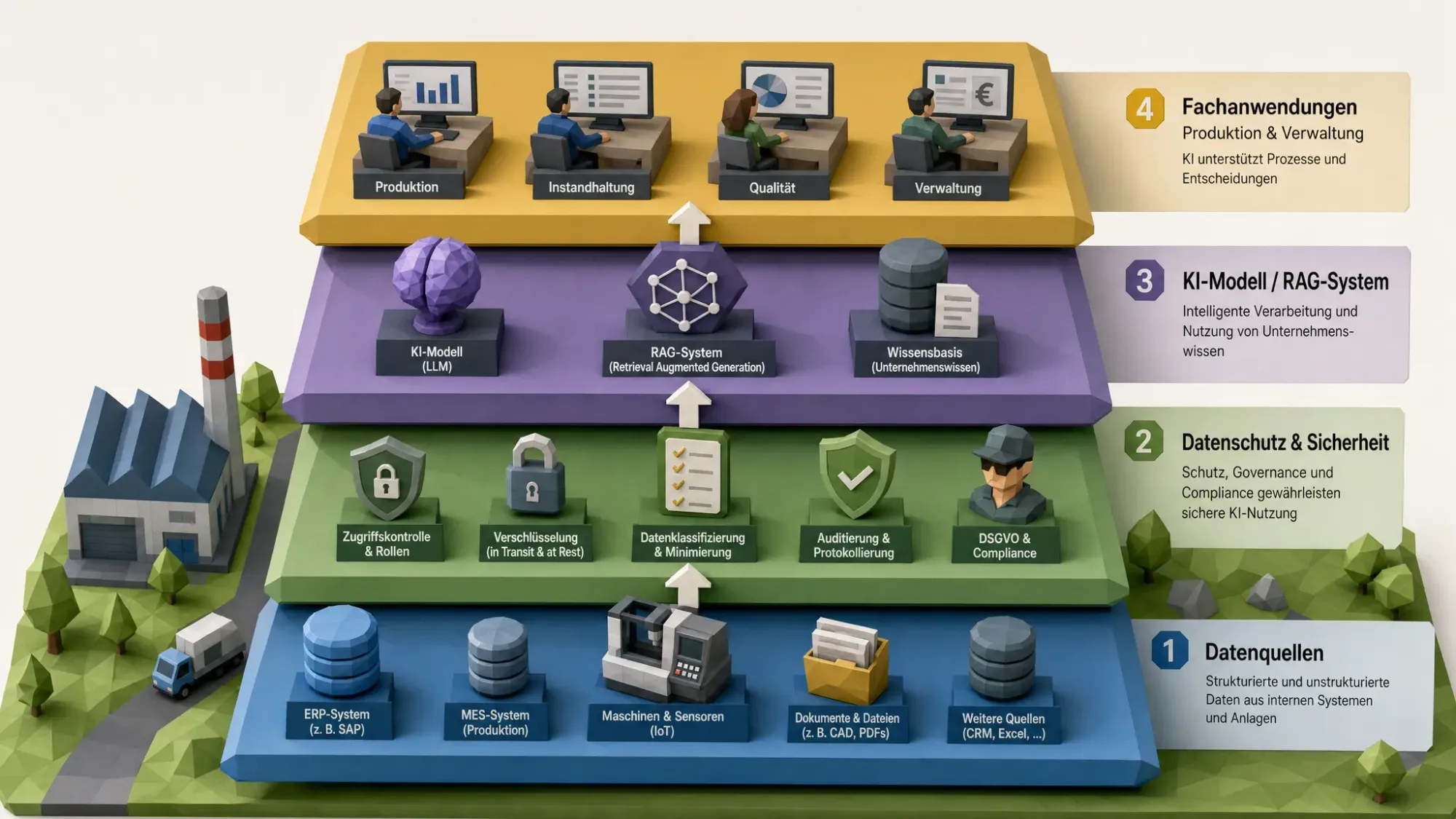
5. Zugriff und Berechtigungen nicht dem Modell überlassen
Ein häufiger Fehler bei KI-Wissenssystemen ist die Annahme, dass ein Modell schon „weiß“, welche Informationen ein Nutzer sehen darf. Das ist gefährlich. Berechtigungen müssen vor dem Modell greifen, nicht erst in der Antwort.
Wenn ein KI-Assistent interne Dokumente durchsucht, muss er dieselben Zugriffsregeln respektieren wie das Quellsystem. Ein Mitarbeiter aus dem Vertrieb sollte nicht über die KI plötzlich Zugriff auf HR-Dokumente, Gehaltsdaten oder vertrauliche Entwicklungsunterlagen erhalten. Berechtigungsbewusstes Retrieval, rollenbasierte Zugriffe und Protokollierung sind daher Pflichtbestandteile einer produktionsreifen Lösung.
6. Ergebnisse validieren und menschliche Kontrolle einbauen
KI kann Vorschläge machen, Muster erkennen und Prozesse beschleunigen. Sie sollte aber nicht unkontrolliert Entscheidungen über Personen treffen. Besonders kritisch sind Anwendungen, die Mitarbeitende bewerten, Bewerbungen vorsortieren, Schichtzuteilungen beeinflussen oder Kundenentscheidungen automatisieren.
Hier sind Human-in-the-Loop-Konzepte wichtig. Das bedeutet: Menschen prüfen, bestätigen oder korrigieren KI-Ergebnisse. Außerdem sollten Unsicherheit, Quellen und Begründungen sichtbar sein. Für viele Mittelstandsprozesse ist nicht die vollautomatische Entscheidung der beste erste Schritt, sondern eine Assistenzfunktion, die Fachkräfte entlastet und gleichzeitig kontrollierbar bleibt.
7. Den Übergang in den Betrieb früh planen
Datenschutz endet nicht mit dem PoC. Im produktiven Betrieb entstehen zusätzliche Anforderungen: Monitoring, Zugriffskontrolle, Modellupdates, Incident-Prozesse, Löschroutinen, Protokollierung, Kostenkontrolle und regelmäßige Qualitätsprüfung.
Viele KI-Initiativen bleiben im Pilotstatus stecken, weil diese Betriebsfragen zu spät geklärt werden. Ein produktionsreifes KI-System braucht daher von Beginn an ein Betriebsmodell. Wie dieser Übergang gelingt, erläutert der Beitrag KI-Deployment im Unternehmen: Vom PoC in den Betrieb.
Besondere Datenschutzfallen bei generativer KI
Generative KI hat den Einstieg in KI stark vereinfacht. Gleichzeitig bringt sie typische Risiken mit sich, die in Unternehmen aktiv gemanagt werden müssen.
Erstens können Prompts vertrauliche oder personenbezogene Daten enthalten. Wenn Mitarbeitende Kundendaten, Verträge, Bewerbungen oder interne E-Mails in nicht freigegebene Tools eingeben, entsteht ein Datenabflussrisiko. Eine klare KI-Nutzungsrichtlinie ist daher kein bürokratischer Luxus, sondern ein notwendiger Schutz.
Zweitens müssen Unternehmen prüfen, ob eingegebene Daten vom Anbieter gespeichert, für Training genutzt oder in Drittstaaten verarbeitet werden. Hier sind Vertragsbedingungen, Auftragsverarbeitung, technische Einstellungen und Datenregionen entscheidend.
Drittens können KI-Antworten falsch, unvollständig oder verzerrt sein. Im Datenschutzkontext ist das besonders relevant, wenn Ergebnisse Personen betreffen. Ein falscher Vorschlag in einer Produktionsanalyse ist ärgerlich. Eine falsche Bewertung eines Mitarbeitenden oder Bewerbers kann rechtlich und kulturell erheblich problematischer sein.
Viertens werden Logs oft vergessen. Auch Protokolle von Prompts, Antworten, Nutzeraktionen und Fehlermeldungen können personenbezogene oder vertrauliche Informationen enthalten. Sie brauchen Speicherfristen, Zugriffsbeschränkungen und Schutzmaßnahmen.
Das Bundesamt für Sicherheit in der Informationstechnik stellt Informationen und Empfehlungen zur sicheren Nutzung von KI bereit. Für Unternehmen lohnt es sich, diese Perspektive mit Datenschutz, IT-Sicherheit und Fachbereichsanforderungen zusammenzuführen.
Typische KI-Use-Cases im Mittelstand und ihre Datenschutzbewertung
Nicht jeder KI-Anwendungsfall ist gleich sensibel. Gerade im industriellen Mittelstand gibt es viele wertvolle Einstiegspunkte mit begrenztem Personenbezug.
| Use Case | Nutzen | Typisches Datenschutzrisiko | Empfehlung für den Start |
|---|---|---|---|
| Predictive Quality | Qualitätsabweichungen früher erkennen | Niedrig bis mittel | Mit Maschinen- und Qualitätsdaten starten, Personenbezug vermeiden |
| Predictive Maintenance | Stillstände reduzieren | Niedrig | Fokus auf Sensordaten und Wartungshistorien, Nutzerlogs trennen |
| Produktionsplanung | Kapazitäten besser nutzen | Mittel | Schicht- und Personaldaten nur falls nötig, Betriebsrat früh einbinden |
| Dokumentenautomatisierung | Rechnungen, Nachweise oder Anträge schneller verarbeiten | Mittel bis hoch | Datenfelder klassifizieren, Maskierung und Löschkonzept definieren |
| Wissensmanagement | Expertenwissen auffindbar machen | Mittel | Berechtigungen aus Quellsystemen übernehmen, Quellen anzeigen |
| HR-Assistenzsysteme | Personalprozesse unterstützen | Hoch | Strenge Zweckbindung, DSFA prüfen, keine Black-Box-Entscheidungen |
| Computer Vision | Sichtprüfung automatisieren | Mittel bis hoch | Kameraposition, Personenbezug und Speicherfristen sehr genau prüfen |
Ein pragmatischer Einstieg liegt häufig dort, wo hoher wirtschaftlicher Nutzen mit begrenztem Personenbezug zusammenkommt. Das kann zum Beispiel Qualitätsprognose, Wartungsoptimierung oder automatisierte Verarbeitung technischer Dokumente sein. Für Use Cases mit Beschäftigtendaten sollte die Governance besonders sorgfältig sein. Weitere Hintergründe zur Einbindung des Betriebsrats finden Sie im Beitrag KI im Unternehmen: Warum Betriebsräte oft auf der Bremse stehen.
Governance: Wer muss bei KI und Datenschutz an den Tisch?
Ein sicheres KI-Projekt braucht klare Verantwortlichkeiten. In der Praxis reicht es nicht, wenn der Fachbereich eine Idee hat und die IT ein Tool testet. Datenschutz, Informationssicherheit, Fachbereich und Management müssen gemeinsam entscheiden, welches Risiko akzeptabel ist und welche Kontrollen nötig sind.
| Rolle | Beitrag im KI-Projekt |
|---|---|
| Geschäftsführung | Priorisiert Use Cases, akzeptiert Restrisiken, stellt Budget und Governance sicher |
| Fachbereich | Definiert Prozessziel, liefert Domänenwissen, validiert Ergebnisse |
| IT | Bewertet Architektur, Integration, Betrieb, Zugriffskonzepte und Schnittstellen |
| Datenschutzbeauftragte | Prüfen Rechtsgrundlagen, Betroffenenrechte, DSFA-Bedarf und Dokumentation |
| Informationssicherheit | Bewertet Bedrohungen, Schutzmaßnahmen, Logging, Incident-Prozesse und Lieferantenrisiken |
| Betriebsrat | Vertritt Beschäftigteninteressen bei Systemen mit möglichem Mitarbeiterbezug |
| KI- oder Datenverantwortliche | Koordinieren Datenqualität, Modellbewertung, Monitoring und kontinuierliche Verbesserung |
Diese Governance muss nicht schwerfällig sein. Gerade im Mittelstand funktioniert oft ein kleines, entscheidungsfähiges Kernteam besser als große Gremien. Wichtig ist, dass KI-Projekte nach nachvollziehbaren Kriterien bewertet werden: Nutzen, Datenlage, Datenschutzrisiko, technische Machbarkeit, Integrationsaufwand und erwarteter ROI.
Datenschutz als Wettbewerbsvorteil statt Innovationsbremse
Datenschutz wird oft als Bremse wahrgenommen. Richtig umgesetzt ist er ein Beschleuniger. Ein Unternehmen, das weiß, welche Daten es hat, wer darauf zugreifen darf und welche Prozesse automatisiert werden können, setzt KI schneller und sicherer um als ein Unternehmen mit ungeklärten Datenbeständen.
Außerdem stärkt ein sauberer Umgang mit Daten das Vertrauen von Kunden, Mitarbeitenden und Partnern. Das ist im Mittelstand besonders wichtig, weil Geschäftsbeziehungen oft langfristig sind und Reputation viel zählt. Wer KI transparent einführt, Betroffene ernst nimmt und sensible Daten schützt, schafft Akzeptanz für Automatisierung.
Auch wirtschaftlich zahlt sich das aus. Früh geklärte Datenschutzfragen reduzieren Nacharbeit, verhindern Tool-Wildwuchs und machen den Schritt vom Experiment zum produktiven System leichter. Datenschutz ist damit nicht nur Compliance, sondern Teil einer belastbaren KI-Strategie.
Wie skillbyte KI und Datenschutz in Projekten zusammenführt
skillbyte unterstützt mittelständische Industrieunternehmen dabei, KI-Lösungen passend zum Unternehmen zu entwickeln, von der ersten Potenzialanalyse bis zur Integration in bestehende Systeme. Dabei stehen nicht einzelne Tools im Vordergrund, sondern der konkrete Prozessnutzen, die Datenlage und eine sichere Umsetzung.
Typische Bausteine sind eine strukturierte Use-Case-Analyse, Datenqualitätsbewertung, ROI-Abschätzung, Proof of Concept, Architekturentscheidung, Integration in vorhandene Systeme und Enablement der Mitarbeitenden. Bei sensiblen Anforderungen können auch On-Premise-Optionen oder kontrollierte hybride Architekturen berücksichtigt werden.
Wichtig: Die juristische Bewertung bleibt Aufgabe Ihrer Datenschutzbeauftragten oder Rechtsberatung. Eine gute technische Umsetzung schafft jedoch die Grundlage dafür, dass Datenschutzanforderungen praktisch erfüllbar werden.
Ein Beispiel für datenschutzbewusste Automatisierung ist die automatisierte ECTS-Anrechnung in Hochschul-Zulassungsverfahren, bei der Dokumente automatisiert verarbeitet und manuelle Aufwände reduziert wurden. Auch wenn der Kontext ein anderer ist, zeigt das Prinzip: KI kann sensible dokumentenbasierte Prozesse beschleunigen, wenn Datenverarbeitung, Qualität und Zweck sauber zusammengedacht werden.
Häufige Fragen zu KI und Datenschutz im Mittelstand
Darf ein mittelständisches Unternehmen personenbezogene Daten für KI nutzen? Ja, aber nur mit klarer Rechtsgrundlage, definiertem Zweck, angemessenen Schutzmaßnahmen und transparenter Verarbeitung. Je sensibler die Daten und je stärker die Auswirkungen auf Personen, desto sorgfältiger müssen Prüfung, Dokumentation und Kontrolle sein.
Muss KI aus Datenschutzgründen immer On-Premise betrieben werden? Nein. On-Premise kann bei besonders sensiblen Daten sinnvoll sein, ist aber nicht immer notwendig. Entscheidend sind Datenart, Risiko, Anbieterbedingungen, Zugriffskontrollen, Verschlüsselung, Datenregion, Auftragsverarbeitung und Betriebsmodell.
Was ist der wichtigste erste Schritt für ein datenschutzsicheres KI-Projekt? Der wichtigste Schritt ist die präzise Definition des Use Cases. Erst wenn Zweck, Prozess und erwarteter Nutzen klar sind, lässt sich bewerten, welche Daten wirklich benötigt werden und welche Schutzmaßnahmen angemessen sind.
Wann ist eine Datenschutz-Folgenabschätzung erforderlich? Eine DSFA ist zu prüfen, wenn eine Verarbeitung voraussichtlich ein hohes Risiko für Rechte und Freiheiten natürlicher Personen mit sich bringt. Das kann besonders bei Beschäftigtendaten, umfangreicher Überwachung, sensiblen Daten oder automatisierten Bewertungen relevant sein.
Wie verhindert man, dass Mitarbeitende sensible Daten in öffentliche KI-Tools eingeben? Unternehmen brauchen klare KI-Richtlinien, freigegebene Werkzeuge, Schulungen und technische Leitplanken. Dazu gehören zum Beispiel Zugriffsbeschränkungen, DLP-Regeln, sichere interne KI-Assistenten und verständliche Beispiele, welche Daten nicht in externe Tools gehören.
Sollte der Betriebsrat bei KI-Projekten immer eingebunden werden? Wenn ein KI-System Beschäftigtendaten verarbeitet oder Verhalten und Leistung von Mitarbeitenden erfassen könnte, sollte der Betriebsrat früh eingebunden werden. Das reduziert Konflikte und verbessert die Akzeptanz im Unternehmen.
KI sicher starten, statt Datenschutzrisiken zu improvisieren
KI und Datenschutz im Mittelstand sind kein Widerspruch. Entscheidend ist ein Vorgehen, das Geschäftsproblem, Datenbasis, Architektur, Governance und Betrieb gemeinsam betrachtet. So entstehen KI-Lösungen, die nicht nur technisch funktionieren, sondern auch rechtlich, organisatorisch und kulturell tragfähig sind.
Wenn Sie prüfen möchten, welche KI-Use-Cases in Ihrem Unternehmen wirtschaftlich sinnvoll und datenschutzbewusst umsetzbar sind, unterstützt skillbyte Sie von der Datenexploration über den Proof of Concept bis zur sicheren Integration. Sprechen Sie mit uns über Ihre Anforderungen und starten Sie mit einem strukturierten, kontrollierbaren KI-Projekt: skillbyte kennenlernen.