

Qualitätssicherung ist im industriellen Mittelstand häufig noch zu stark auf den letzten Prüfpunkt ausgerichtet. Ein Bauteil fällt durch, eine Charge zeigt Grenzwertabweichungen, ein Kunde meldet eine Reklamation. Dann ist der Fehler zwar sichtbar, aber der wirtschaftliche Schaden ist oft schon entstanden: Ausschuss, Nacharbeit, Lieferverzug, zusätzliche Prüfaufwände und im schlimmsten Fall Vertrauensverlust beim Kunden.
KI in der Qualitätssicherung verschiebt diesen Zeitpunkt nach vorn. Statt nur fertige Produkte zu bewerten, erkennt Künstliche Intelligenz auffällige Muster bereits in Prozessdaten, Sensordaten, Bilddaten oder Prüfprotokollen. Der entscheidende Nutzen liegt nicht darin, noch ein weiteres Dashboard zu bauen. Der Nutzen entsteht, wenn Fachbereiche früher reagieren können, bevor aus kleinen Abweichungen echte Qualitätsprobleme werden.
Für Entscheider im Mittelstand ist dabei wichtig: KI-Qualitätssicherung ist kein Selbstzweck und kein reines Forschungsprojekt. Richtig umgesetzt, ergänzt sie bestehende QS-, CAQ-, MES- und ERP-Prozesse, liefert belastbare Frühwarnungen und macht Qualitätsrisiken messbar.
Warum klassische Qualitätssicherung oft zu spät greift
Klassische Qualitätssicherung arbeitet häufig ereignis- oder stichprobenbasiert. Es werden Teile vermessen, Laborwerte geprüft, Sichtkontrollen durchgeführt oder End-of-Line-Tests ausgewertet. Diese Verfahren sind notwendig und bleiben wichtig. Sie haben aber eine strukturelle Grenze: Viele Prüfungen zeigen erst, dass ein Fehler bereits passiert ist.
Besonders kritisch ist das bei Prozessen mit langen Durchlaufzeiten, teuren Rohstoffen, komplexen Rezepturen oder hoher Variantenvielfalt. Wenn eine Abweichung erst nach mehreren Prozessschritten auffällt, ist die Ursache oft schwer nachvollziehbar. War es die Materialcharge? Eine langsam driftende Maschineneinstellung? Ein Werkzeugzustand? Eine Umgebungsbedingung? Oder die Kombination mehrerer Faktoren?
Genau hier setzt KI an. Sie kann große Mengen historischer und aktueller Daten miteinander in Beziehung setzen und Muster erkennen, die in klassischen Regelwerken schwer abzubilden sind. Das ersetzt nicht das Erfahrungswissen von Qualitäts- und Produktionsverantwortlichen. Es macht dieses Wissen aber skalierbarer und ergänzt es um datengetriebene Frühindikatoren.
Die ISO 9001 fordert unter anderem die Steuerung von Prozessen, die Überwachung relevanter Kennzahlen sowie den Umgang mit Nichtkonformitäten und Korrekturmaßnahmen. KI liefert dafür keinen automatischen Normennachweis, kann den Regelkreis aus Messen, Bewerten, Reagieren und Verbessern aber deutlich beschleunigen.
Was KI in der Qualitätssicherung konkret erkennt
KI-Systeme für die Qualitätssicherung suchen nicht nur nach einzelnen Grenzwertverletzungen. Sie lernen Zusammenhänge zwischen Prozessparametern, Produktmerkmalen, Prüfwerten und späteren Fehlerbildern. Dadurch können sie Warnsignale erkennen, bevor ein definierter Grenzwert überschritten wird.
Typische Signale sind zum Beispiel eine langsam driftende Temperaturkurve, ungewöhnliche Vibrationen, veränderte Druckverläufe, Bildfehler auf Oberflächen, Abweichungen in Rezeptur- oder Mischparametern, wiederkehrende Fehlerkombinationen in Prüfberichten oder auffällige Lieferantenmuster in Wareneingangsdaten.
Der Unterschied zu klassischen Regeln ist die Flexibilität. Eine Regel sagt: Wenn Temperatur größer als X, dann Alarm. Ein KI-Modell kann dagegen erkennen: Diese Temperatur ist allein noch unkritisch, aber in Kombination mit Materialcharge, Luftfeuchtigkeit, Maschinengeschwindigkeit und Werkzeugalter steigt die Fehlerwahrscheinlichkeit deutlich.
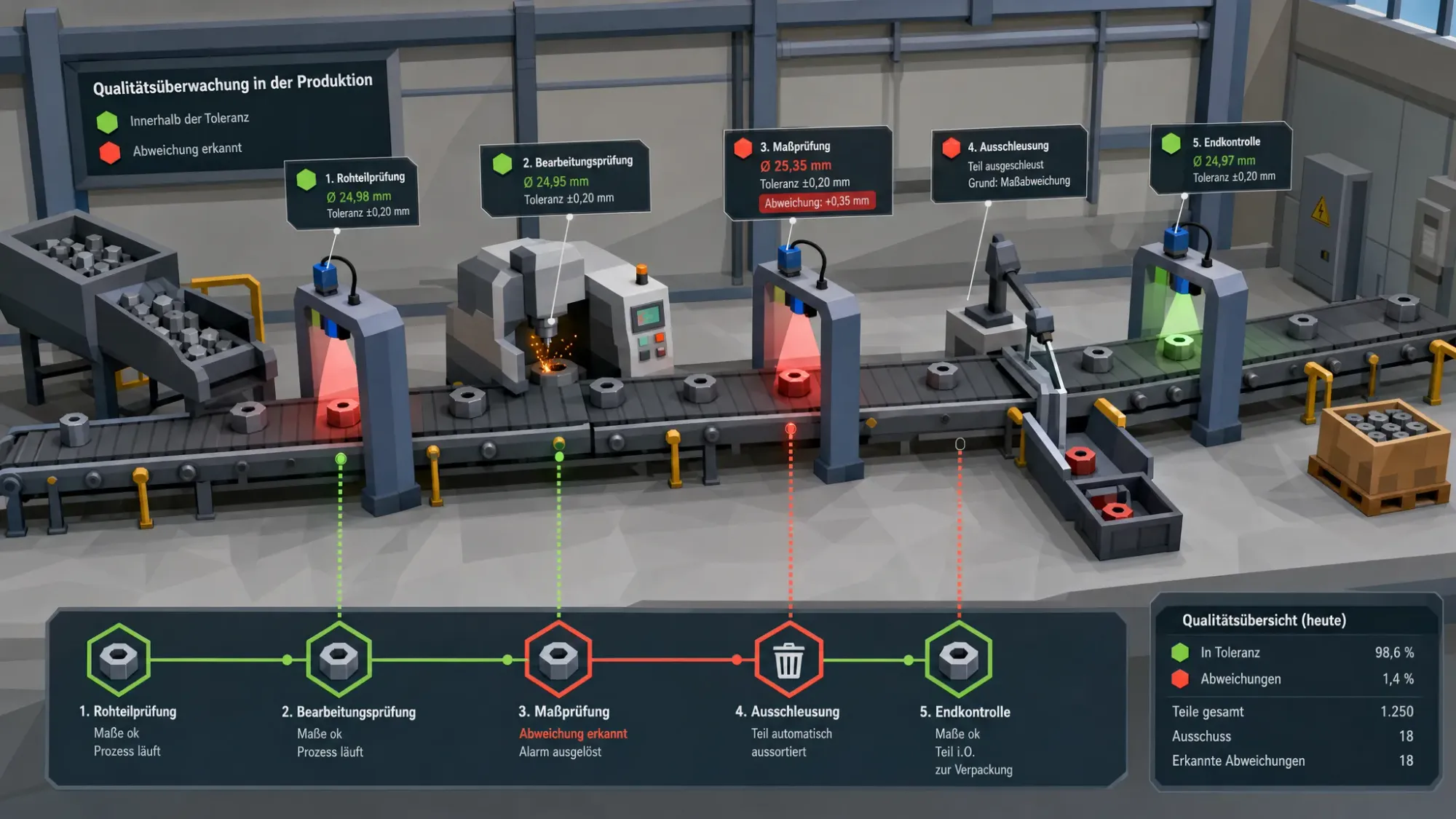
Die wichtigsten KI-Anwendungsfälle in der Qualitätssicherung
Nicht jeder Qualitätsprozess braucht Deep Learning. In vielen mittelständischen Betrieben liefern klassische Machine-Learning-Verfahren, Zeitreihenanalysen oder Anomalieerkennung schneller Nutzen als komplexe Großmodelle. Entscheidend ist die passende Methode zum konkreten Problem.
| Anwendungsfall | Typische Datenbasis | Nutzen für die Qualitätssicherung | Geeignet, wenn |
|---|---|---|---|
| Predictive Quality | Prozessparameter, Prüfwerte, Chargendaten, Maschinendaten | Vorhersage von Qualitätsrisiken vor der Endprüfung | Fehlerursachen in Prozessdaten sichtbar werden können |
| Anomalieerkennung | Sensorzeitreihen, Maschinenzustände, Produktionslogs | Frühe Warnung bei ungewohnten Prozesszuständen | Es gibt viele Normaldaten, aber wenige gelabelte Fehlerfälle |
| Computer Vision | Kamerabilder, Röntgenbilder, Mikroskopiebilder | Automatische Erkennung von Oberflächenfehlern, Maßabweichungen oder Montagefehlern | Sichtprüfung heute manuell, langsam oder inkonsistent ist |
| Root-Cause-Analyse | QS-Berichte, Prozesshistorie, Materialdaten, Schichtdaten | Schnellere Eingrenzung möglicher Fehlerursachen | Viele Einflussfaktoren zusammenspielen |
| Prüfprotokoll-Automation | PDF-Berichte, Messprotokolle, Zertifikate, Reklamationstexte | Weniger manueller Aufwand und konsistentere Auswertung | Dokumente heute händisch geprüft oder übertragen werden |
| Lieferanten- und Wareneingangsprüfung | Lieferantendaten, Prüflose, Reklamationen, Zertifikate | Frühe Erkennung auffälliger Lieferanten- oder Materialmuster | Qualität stark von Zulieferteilen abhängt |
Ein guter Startpunkt ist häufig Predictive Quality, weil hier der wirtschaftliche Nutzen direkt greifbar ist: weniger Ausschuss, weniger Nacharbeit, stabilere Prozesse und schnellere Reaktion bei Abweichungen. In produktionsnahen Umgebungen lässt sich dieser Ansatz mit bestehenden Maschinen-, Labor- und QS-Daten verbinden.
Ein Beispiel dafür ist die skillbyte Case Study zur Optimierung von Prozess- und Produktqualität, in der Echtzeit-Auswertung, Forecasting und Ausreißer-Erkennung genutzt wurden, um Qualitätsprobleme früher sichtbar zu machen. Der konkrete technische Zuschnitt hängt jedoch immer vom Prozess, der Datenlage und den Qualitätszielen ab.
Von der Fehlererkennung zur Fehlervermeidung
Der größte Mehrwert entsteht, wenn KI nicht nur Fehler klassifiziert, sondern Entscheidungen vorbereitet. Dafür braucht es drei Stufen.
Zuerst erkennt das System Abweichungen. Das kann ein ungewöhnliches Muster in Sensordaten sein, ein Bildfehler oder eine statistische Auffälligkeit in Prüfwerten. In dieser Phase geht es darum, nicht nur harte Grenzwertverletzungen zu melden, sondern auch schwache Signale sichtbar zu machen.
Im zweiten Schritt bewertet das System das Risiko. Nicht jede Abweichung ist gleich kritisch. Eine gute KI-Lösung priorisiert Meldungen nach Eintrittswahrscheinlichkeit, möglichem Schaden und Prozesskontext. Dadurch entstehen nicht mehr Alarme, sondern bessere Alarme.
Im dritten Schritt wird die Reaktion in den Prozess integriert. Das kann eine Meldung an die Schichtleitung sein, ein zusätzlicher Prüfauftrag, eine Anpassung eines Prozessparameters, die Sperrung einer Charge zur Prüfung oder eine Empfehlung für die Ursachenanalyse. Wichtig ist: In regulierten oder sicherheitsrelevanten Bereichen sollte der Mensch weiterhin die finale Entscheidung treffen, zumindest solange das System nicht umfassend validiert ist.
Der Maßstab für KI in der Qualitätssicherung ist nicht die schönste Modellarchitektur, sondern die Frage, ob Qualitätsentscheidungen früher, verlässlicher und wirtschaftlicher getroffen werden.
Welche Daten wirklich benötigt werden
Viele KI-Projekte scheitern nicht am Algorithmus, sondern an der Datenbasis. Qualitätssicherung ist besonders anspruchsvoll, weil Daten aus unterschiedlichen Systemen zusammengeführt werden müssen: Maschinensteuerung, SCADA, MES, ERP, CAQ, Labor, Wareneingang, Reklamationsmanagement und manchmal auch Excel-Dateien.
Dabei geht es nicht darum, sofort eine perfekte Datenplattform aufzubauen. Für einen belastbaren Proof of Concept reicht oft ein klar begrenzter Prozessabschnitt mit ausreichend historischen Daten. Wichtig ist, dass die Daten die reale Prozesslogik abbilden.
| Datenanforderung | Warum sie wichtig ist | Typische Prüffrage |
|---|---|---|
| Eindeutige Zeitstempel | KI muss Ereignisse korrekt entlang des Prozesses zuordnen | Sind Messwerte, Prozessschritte und Prüfungen zeitlich synchronisierbar? |
| Chargen- oder Seriennummern | Qualitätsabweichungen müssen Produkten oder Losen zugeordnet werden | Können Prozessdaten späteren Prüfergebnissen eindeutig zugeordnet werden? |
| Ausreichende Fehlerhistorie | Überwachtes Lernen benötigt Beispiele für gute und schlechte Fälle | Gibt es dokumentierte Ausschuss-, Nacharbeits- oder Reklamationsfälle? |
| Kontextdaten | Ursachen liegen oft in Material, Werkzeug, Schicht, Rezeptur oder Umgebung | Welche Einflussfaktoren werden heute bereits erfasst? |
| Datenqualität | Fehlende, doppelte oder inkonsistente Werte verfälschen Modelle | Wie vollständig und plausibel sind die relevanten Datenfelder? |
| Prozessverständnis | Fachwissen verhindert falsche Korrelationen | Können QS und Produktion erklären, welche Zusammenhänge fachlich plausibel sind? |
Gerade im Mittelstand ist eine frühe Datenqualitätsbewertung entscheidend. Sie zeigt, ob ein KI-Projekt direkt starten kann, ob zuerst Schnittstellen geschaffen werden müssen oder ob ein kleinerer Use Case sinnvoller ist.
Weitere praxisnahe Einsatzfelder im Produktionsumfeld finden Sie im Beitrag KI in der Produktion: 6 Hebel für mehr Effizienz.
Wie ein pragmatisches KI-Projekt in der Qualitätssicherung aussieht
Ein KI-Projekt sollte nicht mit der Frage beginnen, welches Modell eingesetzt wird. Es sollte mit einem konkreten Qualitätsproblem beginnen. Zum Beispiel: Welche Fehler verursachen die höchsten Kosten? Wo entstehen wiederkehrende Reklamationen? Welche Prüfungen dauern zu lange? Wo erkennen Mitarbeitende Muster, die heute nicht systematisch genutzt werden?
Ein praxistaugliches Vorgehen umfasst sechs Schritte.
- Qualitätsproblem eingrenzen: Definieren Sie einen klaren Fehlerfall, einen Prozessabschnitt und eine Zielgröße, etwa Ausschussrate, Nacharbeitsquote, Reklamationen oder Prüfzeit.
- Business Case formulieren: Bewerten Sie die wirtschaftliche Relevanz anhand von Ausschusskosten, Nacharbeit, Lieferverzug, Prüfaufwand und Kundenrisiko.
- Datenlage prüfen: Analysieren Sie, ob Prozess-, Prüf- und Kontextdaten ausreichend vollständig, verknüpfbar und historisch verfügbar sind.
- Proof of Concept umsetzen: Trainieren und testen Sie ein Modell auf historischen Daten und validieren Sie die Ergebnisse gemeinsam mit QS und Produktion.
- Shadow Mode nutzen: Lassen Sie das System zunächst parallel zum bestehenden Prozess laufen, ohne automatische Eingriffe, um Trefferqualität und Akzeptanz zu prüfen.
- Integration planen: Binden Sie Warnungen, Empfehlungen und Monitoring in bestehende Systeme und Verantwortlichkeiten ein.
Der Proof of Concept sollte nicht nur eine technische Genauigkeit ausweisen. Er muss zeigen, ob die Vorhersagen im Prozess handlungsfähig sind. Eine Warnung ist nur dann wertvoll, wenn sie früh genug kommt, verständlich ist und eine realistische Reaktion ermöglicht.
Für die Business-Case-Seite lohnt sich ein strukturierter Ansatz, wie im Beitrag KI-Projekt starten: Von der Idee zum belastbaren Business Case beschrieben.
KPIs: Woran Sie den Erfolg messen sollten
KI in der Qualitätssicherung muss an operativen Kennzahlen gemessen werden, nicht nur an Modellmetriken. Modellkennzahlen wie Precision, Recall oder Fehlalarmrate sind wichtig, aber sie reichen nicht aus. Entscheidend ist die Wirkung im Qualitätsprozess.
| KPI | Bedeutung | Warum sie für Entscheider relevant ist |
|---|---|---|
| Ausschussquote | Anteil nicht verwendbarer Teile oder Chargen | Direkter Kosteneffekt |
| Nacharbeitsquote | Anteil der Produkte mit zusätzlichem Bearbeitungsaufwand | Einfluss auf Kapazität und Durchlaufzeit |
| Reklamationsrate | Qualitätsprobleme nach Auslieferung | Wirkung auf Kundenbindung und Gewährleistungskosten |
| Frühwarnzeit | Zeit zwischen KI-Warnung und tatsächlicher Abweichung | Zeigt, ob präventives Handeln möglich ist |
| False-Positive-Rate | Anteil unnötiger Alarme | Wichtig für Akzeptanz im Shopfloor |
| Erkennungsrate kritischer Fehler | Anteil korrekt erkannter relevanter Fehler | Entscheidend für Risiko- und Qualitätssteuerung |
| Prüfaufwand pro Los | Zeit oder Kosten für Prüfungen | Hebel für Produktivität in QS und Labor |
Eine sinnvolle ROI-Betrachtung kombiniert harte Effekte und Risikoeffekte. Harte Effekte sind zum Beispiel weniger Ausschuss, reduzierte Nacharbeit oder geringerer Prüfaufwand. Risikoeffekte sind schwerer zu beziffern, aber strategisch relevant: weniger Kundeneskalationen, stabilere Lieferfähigkeit und bessere Auditfähigkeit.
Wichtig ist, vor dem Projekt eine Baseline festzulegen. Ohne Ausgangswerte lässt sich später nicht seriös beurteilen, ob KI tatsächlich verbessert hat oder ob Schwankungen im normalen Prozessrauschen liegen.
Datenschutz, Sicherheit und Governance nicht nachträglich klären
Qualitätsdaten sind oft weniger personenbezogen als HR- oder Vertriebsdaten, aber sie sind geschäftskritisch. Rezepturen, Prozessparameter, Prüfmethoden, Lieferantendaten und Produktionsmengen gehören zu den sensibelsten Informationen eines Industrieunternehmens. Deshalb sollten Architektur und Betriebsmodell früh geklärt werden.
Für viele Mittelständler sind On-Premise- oder private Cloud-Architekturen relevant, insbesondere wenn Produktionsdaten nicht an externe Plattformen übertragen werden sollen. Auch Rollen- und Rechtekonzepte sind wichtig: Nicht jeder Nutzer sollte jede Qualitätsanalyse, Lieferantenbewertung oder Prozesshistorie einsehen können.
Regulatorisch lohnt sich ein genauer Blick auf den EU AI Act. Nicht jede KI-Anwendung in der Qualitätssicherung ist automatisch Hochrisiko-KI. Sobald KI jedoch sicherheitsrelevante Entscheidungen beeinflusst, Teil eines regulierten Produkts wird oder personenbezogene Daten verarbeitet, müssen Einstufung, Dokumentation, menschliche Aufsicht und Risikomanagement sauber geprüft werden.
Auch der Betriebsrat kann relevant sein, wenn KI-Systeme Rückschlüsse auf Beschäftigte, Schichtleistung oder individuelle Arbeitsweise ermöglichen. Deshalb sollten Datenschutz, IT-Sicherheit, Fachbereich, QS und Arbeitnehmervertretung nicht erst beim Rollout eingebunden werden. Mehr dazu finden Sie im Beitrag KI und Datenschutz im Mittelstand sicher zusammenbringen.
Häufige Fehler bei KI-Qualitätssicherung
Der erste Fehler ist ein zu breiter Scope. Wer direkt die gesamte Qualitätssicherung automatisieren will, verliert schnell Fokus. Besser ist ein klarer Prozessabschnitt mit messbarem Fehlerbild und wirtschaftlicher Relevanz.
Der zweite Fehler ist die reine Modellfixierung. Ein Modell mit guter Testgenauigkeit bringt wenig, wenn die Warnung zu spät kommt, nicht verstanden wird oder nicht in den Arbeitsablauf passt. Deshalb müssen QS, Produktion und IT von Beginn an gemeinsam definieren, wie eine KI-Erkenntnis praktisch genutzt wird.
Der dritte Fehler ist eine unterschätzte Datenintegration. Viele relevante Informationen liegen in unterschiedlichen Systemen oder sogar in manuellen Dateien. Das ist kein Ausschlusskriterium, muss aber im Aufwand und in der Architektur berücksichtigt werden.
Der vierte Fehler ist fehlendes Monitoring. Produktionsprozesse verändern sich: neue Materialien, neue Maschinenparameter, neue Lieferanten, veränderte Umgebungsbedingungen. Ein KI-Modell muss deshalb überwacht und regelmäßig überprüft werden. Sonst nimmt die Qualität der Vorhersagen mit der Zeit ab.
Der fünfte Fehler ist mangelnde Akzeptanz im Shopfloor. Wenn Mitarbeitende die Warnungen nicht nachvollziehen können oder zu viele Fehlalarme erhalten, wird das System umgangen. Erklärbarkeit, klare Eskalationswege und ein Human-in-the-Loop sind daher keine Nebenthemen, sondern Erfolgsfaktoren.
Häufige Fragen zu KI in der Qualitätssicherung
Ersetzt KI die klassische Qualitätssicherung? Nein. KI ergänzt bestehende Prüf- und QS-Prozesse. Sie hilft, Muster früher zu erkennen, Prüfungen zu priorisieren und Ursachen schneller einzugrenzen. Normative Prüfungen, Freigaben und fachliche Entscheidungen bleiben weiterhin relevant.
Brauchen wir für KI-Qualitätssicherung große Datenmengen? Nicht immer. Für einige Verfahren, etwa Computer Vision mit vielen Fehlerklassen, sind größere gelabelte Datenmengen hilfreich. Für Anomalieerkennung oder Forecasting können auch vorhandene Normaldaten und gut strukturierte Prozessdaten ausreichen. Entscheidend ist die Qualität und Verknüpfbarkeit der Daten.
Welche Abteilung sollte ein solches Projekt führen? Erfolgreich wird es meist als gemeinsames Projekt von Qualitätssicherung, Produktion, IT und Geschäftsführung. QS kennt die Fehlerbilder, Produktion versteht den Prozess, IT bewertet Integration und Sicherheit, die Geschäftsführung priorisiert den wirtschaftlichen Nutzen.
Wie schnell zeigt sich ein Nutzen? Das hängt von Datenlage, Prozesskomplexität und Use Case ab. Ein gut abgegrenzter Proof of Concept kann oft relativ schnell zeigen, ob die Daten ein verwertbares Signal enthalten. Der volle Nutzen entsteht jedoch erst, wenn die Lösung in den operativen Prozess integriert und sauber überwacht wird.
Ist KI in der Qualitätssicherung auch für kleinere Mittelständler sinnvoll? Ja, wenn ein relevantes Qualitätsproblem vorliegt und Daten zumindest teilweise verfügbar sind. Gerade kleinere Unternehmen profitieren davon, Erfahrungswissen systematischer nutzbar zu machen und knappe QS-Ressourcen auf die kritischsten Fälle zu konzentrieren.
Nächster Schritt: Qualitätsrisiken datenbasiert prüfen
KI in der Qualitätssicherung lohnt sich dort, wo Fehler heute zu spät erkannt werden, Prüfaufwände steigen oder Ursachenanalysen zu lange dauern. Der pragmatische Start ist keine große KI-Strategie, sondern eine strukturierte Bewertung konkreter Qualitätsprobleme, vorhandener Daten und erwartbarer Effekte.
skillbyte unterstützt mittelständische Industrieunternehmen von der Use-Case-Auswahl über Datenqualitätsprüfung, Proof of Concept und ROI-Schätzung bis zur Integration in bestehende Systeme. Dabei stehen passgenaue KI-Lösungen, Datensicherheit, Enablement und realistische Umsetzbarkeit im Vordergrund.
Wenn Sie prüfen möchten, wo KI in Ihrer Qualitätssicherung den größten Hebel hat, informieren Sie sich über KI-Lösungen für den industriellen Mittelstand und starten Sie mit einer belastbaren Analyse Ihrer Qualitäts- und Prozessdaten.

